云不仅重要; 对许多公司来说,这是关键任务。我所谈论的越来越多的IT和业务领导者将公共云视为其数字化转型战略的核心组成部分 - 将其作为混合云或公共云实施的一部分。
这提高了云可靠性的标准,因为云中断意味着业务无法获得重要的服务。如果这是关键业务服务,则该公司可能无法在该关键服务脱机时运行。
由于云的重要性日益增加,因此买家必须能够了解云提供商的可靠性数量。面临的挑战是云提供商不会以一致的方式披露中断情况。事实上,有些人很难混淆任何有意义的结论。
报告的云中断时间并不总是反映实际的停机时间
Microsoft Azure和Google Cloud Platform(GCP)通常都提供有关日期和时间的信息,但仅提供有关受影响服务的高级数据以及有关区域影响的稀疏信息。问题在于难以理解整体可靠性。例如,如果Azure报告一个小时的中断影响三个区域中的五个服务,则该网站可能只显示一个小时。实际上,这是15个小时的总停机时间。
在Azure,GCP和Amazon Web Services(AWS)之间,Azure是最不起眼的,因为它提供的信息量最少。GCP在提供服务级别的细节方面做得更好,但往往会因区域信息而变得模糊不清。有时候很清楚哪些服务不可用,有时则不然。
AWS具有最精细的报告,因为它显示了每个区域中的每个服务。如果发生影响三项服务的事件,则所有这三项服务都会亮起红色。如果这些不可用一小时,AWS将记录三个小时的停机时间。
云提供商之间的另一个不一致是可用的历史停机数据量。有一段时间,所有三家云供应商都提供了一年的停电视图。GCP和AWS仍然这样做,但Azure 在过去一年中的某个时间只移动了90天。
Azure的停机时间明显高于GCP和AWS
下一个显而易见的问题是谁的停机时间最长?为了回答这个问题,我与第三方公司合作,该公司不断直接从供应商网站收集停机信息。我亲自审阅了这些信息,并可以验证其准确性。根据供应商自己报告的数据,从2018年初到2019年5月3日,AWS领先于仅有338小时的停机时间,其次是GCP,密切关注361.Microsoft Azure的自我报告总数高达1,934小时停机时间。
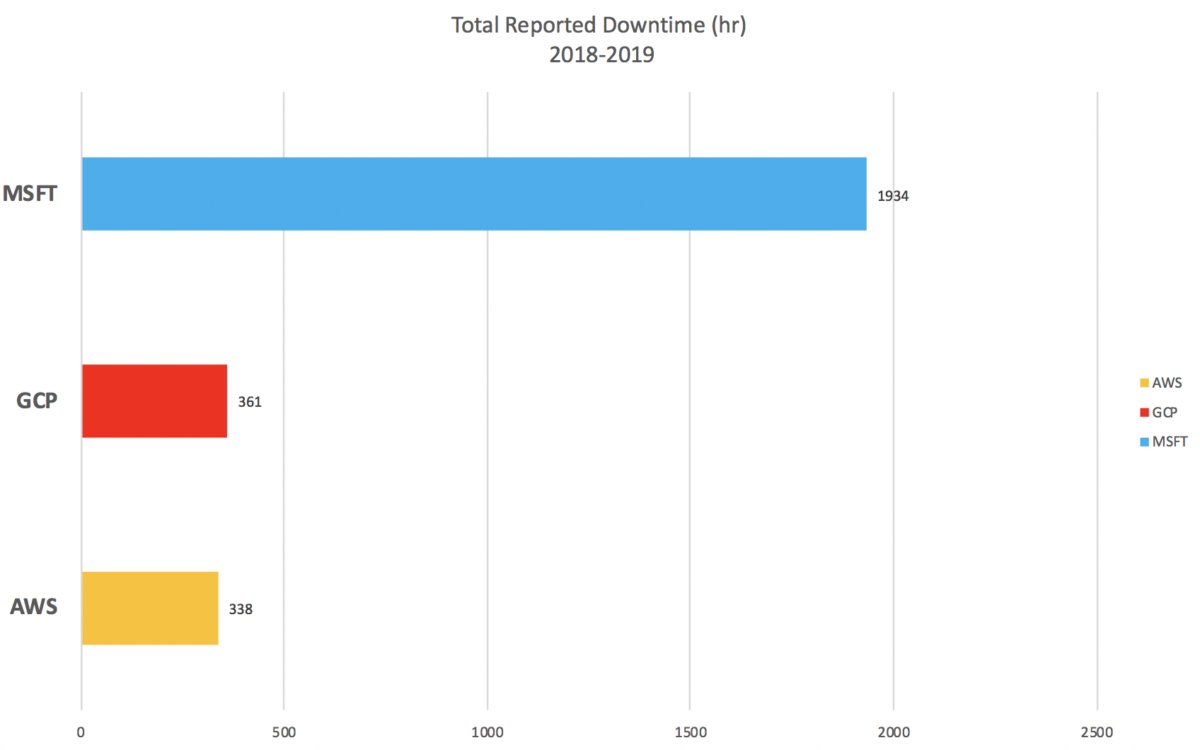
关于这些数字的几点。首先,这是来自供应商网站的自我报告数据的汇总,这不是“真实”数字,因为区域信息或服务粒度有时会被模糊。如果一个小时的服务不可用,并且在网站上报告了一个小时但是它跨越了五个区域,则应该使用正确的五个小时。但是对于这个计算,我们只使用了一个小时,因为这是自我报告的。
因此,这些数字对Microsoft最有利,因为它们提供的区域信息量最少。这些数字对AWS最不利,因为它们提供的粒度最大。此外,我相信AWS在大多数地区拥有最多的服务,因此他们有更多的停机机会。
我们曾考虑对数据进行规范化,但这需要大量的工作来破坏每个区域每个服务的停机时间。我可能会选择在将来这样做,但目前,供应商报告的视图是相对性能的良好指标。
另一个重点是,只使用基础架构即服务(IaaS)服务来计算停机时间。如果Google街景或Bing地图发生故障,大多数企业都不会关心,因此将这些数字推出是不公平的。
SLA与可靠性无关
鉴于当今云服务的重要性,我希望看到每个云提供商在其网站上的某个地方发布12个月的停机总时间,以便客户可以进行“苹果对苹果”的比较。这显然不是确定使用哪个云提供商的唯一因素,但它是更重要的一个。
此外,买家应该意识到服务级别协议(SLA)和停机时间之间存在很大差异。云运营商可以承诺他们想要的任何东西,甚至提供100%的SLA,但这只意味着他们需要在服务不可用时偿还业务。我谈过的大多数IT领导者都表示,当服务中断时他们收回的几块钱只是停电实际花费的一小部分。
测量两次并切一次以最大限度地减少业务中断
如果您正在阅读本文并且您正在研究云服务,那么为了方便起见,不仅要轻松做出购买决定,这一点非常重要。许多公司都关注Azure,因为Microsoft将Azure信用作为企业协议(EA)的一部分。我采访了几家走阻力最小的公司,但他们对可用性感到失望,然后转而使用AWS或GCP,这可能会产生破坏性影响。
我当然不是说不要购买Microsoft Azure,但重要的是要做好功课,以了解您在需要的地区考虑的服务的历史性能。供应商网站上的信息可能无法说明全部情况,因此必须进行必要的尽职调查,以确保在购买之前了解您所购买的产品。

